Research Compute Infrastructure
Our research lab needed a more scalable approach to sharing computing resources among researchers. To address this, we built a scalable computing infrastructure on Kubernetes. Researchers can request resources from the pool and use a familiar workflow with Jupyter Notebooks. Resources are returned to the pool once a task is complete or idle for too long.
Introduction
Recent technological advances have transformed education, elevating the quality of teaching and learning. Jupyter Notebooks have emerged as a leading tool for interactive computing, programming, and data analysis (Perkel 2018; Mendez et al. 2019; Granger et al. 2021). However, hardware limitations became a significant hurdle when handling larger research projects. While public cloud services are an option, they come with notable drawbacks. In response, we developed a private cloud solution for our lab using Kubernetes. This solution addresses cost and security concerns while ensuring adaptability. Through this technology, we have enabled efficient app management, scalability, and resource flexibility.
Jupyter Notebooks
A Jupyter Notebook is an open document format based on JSON1. Notebooks are organized into a sequence of cells, with each cell containing code, descriptive text, equations, and rich outputs (e.g., text displays, tables, audio, images, and animations). Tools like JupyterLab provide a platform for interactive code execution, data analysis, and documentation, all within a single interface, culminating in a Jupyter Notebook. These notebooks support various programming languages (e.g., Python, R, Scala, C++) and allow users to write and execute code cells iteratively (using REPL2 or WETL3 approaches), offering immediate visibility of intermediate results. This facilitates the creation of narrative-driven data analyses, educational materials, and interactive presentations. Due to their versatility and interactivity, Jupyter Notebooks are a robust teaching tool for learning, conducting data science, and computer research.
Because of these remarkable features, we decided to incorporate Jupyter Notebooks into our research lab’s educational and research processes. We encouraged students and researchers to use Jupyter Notebooks to document their work and share it more easily with others.
Scalability
However, for large-scale projects involving hefty data processing on personal computers, using Jupyter Notebooks becomes a significant challenge. We frequently run into hardware limitations like storage space, RAM, processing power, and access to compute accelerators, which can hinder or even halt our progress. These projects are typically in the early stages of research, analysis, or prototyping, so intensive optimizations are impractical because they can slow down experimental development. Two potential solutions emerge: running Jupyter Notebooks on the grid, HPC infrastructure, or cloud services.
HPC infrastructure, like SLING in Slovenia or EuroHPC on a European level, offers immense computational power. However, given that HPCs are significant investments, queue management solutions like SLURM are employed in the HPC world to optimize their use. Computation tasks must be pre-packaged with metadata, code, and input data. These tasks then join a waiting list. This approach is not aligned well with data-driven research, which aims for interactive programming and quick feedback, limiting the full utilization of Jupyter Notebooks. Hence, cloud services become a more common choice for these notebooks.
Public cloud platforms like Google Colab and Kaggle have popularized Jupyter Notebook usage. Users can access the service anytime without queues, edit notebooks, and utilize cloud computing resources, all via a browser. Both services are freely accessible in a limited version. However, due to high user demand, these platforms sometimes limit computational resources, affecting service quality. Alternatives include custom paid services in the public cloud (e.g., AWS, Azure, GCP, Alibaba Cloud) that tailor infrastructure to customer needs. However, public cloud services have drawbacks, including high rental costs, unpredictable market-affected expenses, and security concerns when handling sensitive data.
Private clouds are an alternative to the public cloud, addressing cost and security challenges. They are crucial for research labs and companies dealing with sensitive data or requiring high adaptability. It grants organizations more transparency and cost control based on their needs and capabilities. Despite the initial technical knowledge and infrastructure investment requirements, private clouds offer enhanced security, control, and flexibility, leading to more predictable costs in the long run.
Several technologies are available to set up a private cloud, including commercial options (e.g., VMware vSphere, Red Hat OpenShift, IBM Cloud Private) and open-source solutions (e.g., The Littlest JupyterHub, OpenStack, Eucalyptus, Kubernetes, or using Docker Compose [reference design, gcerar/jupyterhub-docker]). Among the open-source options, Kubernetes is the most popular solution.
Kubernetes (abbreviated as K8s) is an open-source platform designed for the automation, management, and deployment of applications within containers. Its advanced orchestration features allow for efficient application management, automatic scaling, monitoring of their performance, and high availability. It can simplify the development and maintenance of complex cloud-based applications.
Contrary to Docker and Docker Compose, which primarily focus on building, storing, and running individual containers, Kubernetes offers a much more comprehensive platform for managing containers across expansive environments that span multiple computing nodes. While Docker provides easy creation and operation of individual containers, and docker-compose allows defining multiple containers as application units, Kubernetes facilitates the management of entire clusters of these application units throughout their life cycle, which includes automatic deployment, dynamic adjustments based on load, recovery in case of errors, and more advanced service and network management.
In our research lab, due to the growing computational demands prevalent in data science and the desire to retain the recognizable workflow present in Jupyter Notebooks, we have developed our private cloud solution based on Kubernetes technology.
The following sections will present a private cloud setup featuring Jupyter Notebooks built on top of open-source solutions. The user experience closely resembles that of existing paid cloud services. The private cloud must meet the following requirements:
System Scalability: The cloud should allow for easily adding computing nodes to the cluster without disrupting the operational system, supporting larger research projects or teaching groups.
Efficient Resource Management: The system must enable precise allocation of resources to users. In this context, an administrator can define a balance between a lax and strict resource allocation policy.
Enhanced Collaboration Experience: The system should allow for straightforward sharing of Jupyter Notebooks among users, promoting collaboration on joint projects and idea exchange between researchers and students.
No Waiting Queues: The system should eliminate waiting queues, offering users immediate access to computational resources to the best of their capacity.
Architecture
We decided to base our private cloud on the Kubernetes platform to meet system scalability and resource management requirements, aiming to enhance the functionality, accessibility, and sharing of Jupyter Notebooks (Bussonnier 2018) within the Kubernetes private cloud. In this section, we will delve deeper into the system’s architecture that integrates services and elaborate on the design decisions. Subsequently, we describe the individual services within our infrastructure.
| Service | Solutions (Used in bold) |
|---|---|
| Turnkey solution? | Custom, NVIDIA DeepOps |
| Basic Infrastructure | |
| Operating System | Ubuntu, RHEL, NixOS, Talos |
| Data Storage | ZFS, GlusterFS, Lustre, CEPH, iSCSI |
| System Management | Ansible, Terraform, Puppet, Chef |
| Internal Services | |
| K8s Distribution | vanilla, MicroK8s, OpenShift, Rancher |
| K8s Installation | Helm, Kustomize |
| Network Manager | Calico, Canal, Flannel, Weave |
| Data Manager | csi-driver-nfs, Rook, OpenEBS |
| Traffic Balancing | MetalLB, cloud provider specific |
| Traffic Manager | Nginx, Traefik |
| GPU Manager | NVIDIA GPU-Operator |
| Services for Users | |
| JupyterHub Manager | Z2JH (Zero-to-JupyterHub) |
| Metrics and Monitoring | kube-prometheus-stack, InfluxDB |
Table 1, in its first column, lists all the services required for system operation. The second column lists the open-source solutions that can provide these services. Bolded services indicate those selected and used in our private cloud. We made our choices based on specific criteria. We first surveyed technologies and solutions utilized in related projects. We further narrowed our selection to open-source solutions tested in private clouds on native infrastructure. A significant factor in our decision-making was also an insight into the popularity of the projects, gauged by the number of stars in repositories, the number of forks of the project, and the level of development activity on GitHub/GitLab. In our decision-making process, we didn’t follow a single empirical metric but took multiple factors into account to ensure a comprehensive assessment of solutions.
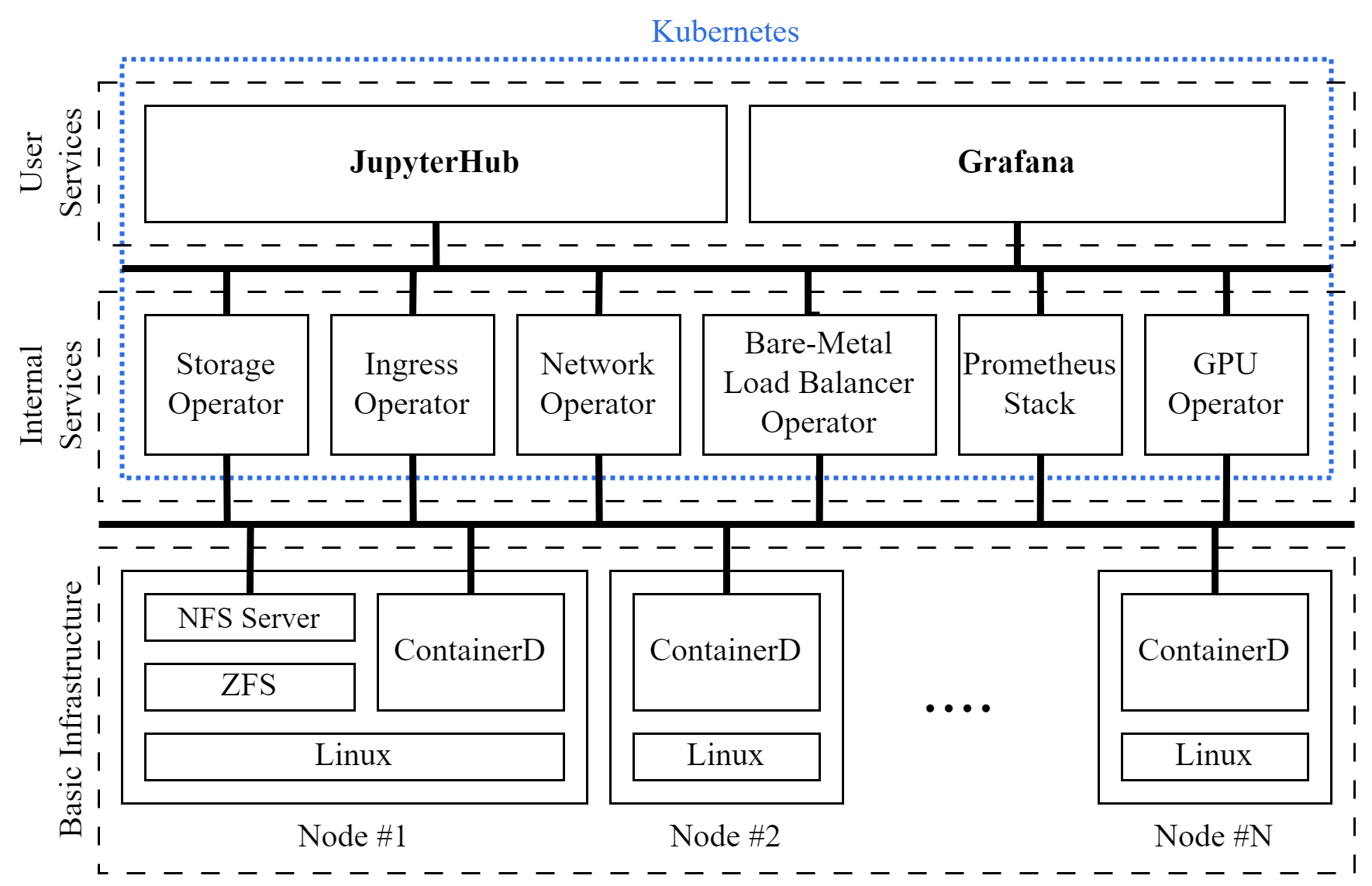
The diagram in Figure 1 provides a high-level representation of our private cloud and its infrastructure across three levels. The first level comprises heterogeneous computing nodes, forming the foundational infrastructure. Each node operates its operating system, running a portion of the Kubernetes platform. The second level encompasses internal Kubernetes services, which are essential for operation and never directly accessed by users. The final third level includes the services availed by end-users.
Turnkey Solution?
When planning the private cloud, we initially explored turnkey solutions, including NVIDIA DeepOps. Despite its advantages, we built our custom solution for the following reasons. While DeepOps is an excellent turnkey solution with maintained source code on GitHub and offers commercial support, initial setup requires configuration file adjustments, including Ansible scripts for automated (re)configuration of installed Linux distribution. Its complexity discouraged us from further investing our time in tinkering with it.
One of our biggest concerns was the intricate solution that tries to be versatile and “simple”. However, this inevitably leads to hiding functionalities and, in case of issues, jumping around documentation of multiple unrelated internally used tools. Despite proclaimed simplicity, troubleshooting or upgrade problems require manual intervention, where a thorough understanding of Linux, DeepOps, its internal tooling, and their interactions is necessary for system control. Therefore, we decided to start with a minimalist solution and, over time, plan to expand the system to understand the infrastructure’s operation better.
Foundation Infrastructure
In this section, we discuss the foundation infrastructure of our private cloud solution. We’ll go through these building blocks, including the selection of container management tools and resource sharing, which are vital for the operation of the Kubernetes platform.
Operating System: We chose Ubuntu Server based on the Debian Linux distribution for our system. The advantage of widely used Debian-based Linux distributions is the abundance of available knowledge resources and support, making problem-solving more accessible. Among alternatives, like declarative binary reproducible NixOS and RHEL-based distributions, we also considered the Talos distribution specialized for Kubernetes. However, we preferred to stick with Ubuntu Server due to the Talos project’s novelty and associated risks.
Container Management: For container management, we selected ContainerD, also used in the DeepOps solution and officially supported by NVIDIA. It is an open-source tool that implements the CRI interface for communication between the operating system and Kubernetes for efficient and reliable container management.
Data Storage: For data storage, we chose ZFS, which resides on one of the nodes. Although solutions like HDFS, Gluster, Lustre, or Ceph are far more common in the HPC world, they require dedicated infrastructure and tools to offer features offered by ZFS out-of-the-box. Features include checkpoints, data deduplication, compression, a COW (copy-on-write) system to prevent data loss during writing, immunity to silent bit-rot, the ability to use disks as redundancy for mechanical failures, and the use of fast SSD devices as a cache. It also allows easy manual intervention in the event of incidents. However, at the time of writing, ZFS does not stretch across multiple nodes, posing a risk of cluster failure in case of a data-storing node’s malfunction (single point of failure). There is an ongoing effort to implement ZFS’ distributed RAID (dRAID) [src].
To access ZFS storage from Kubernetes, we used the NFS server, which is part of the Linux kernel. We chose NFS because it is one of the few methods that allow multiple containers to bind to the same mounting point (see table).
System Management: For remote management and node configuration, we use Ansible maintained by Red Hat. We selected it due to its prevalence in other significant open-source projects and positive experiences from past projects.
Kubernetes
In Kubernetes, everything operates as a service. These services provide various functionalities that enhance Kubernetes capabilities, such as storage access, CPU and GPU allocation, traffic management, and connecting services within a mesh network.
To support specific functionalities, appropriate services (much like operating system drivers) must be installed. These specialized services, often called “operators” in Kubernetes terminology [src], are essential. They not only deploy and manage functionalities but also respond to issues. Operators enhance Kubernetes by interfacing with standardized and version-controlled APIs.
Put simply, operators are deployed as controller pods (containers) that watch for changes to custom Kubernetes resources and react accordingly. They function as an intermediary layer, implementing application-specific logic that extends Kubernetes beyond its built-in capabilities.
Internal Services
In Kubernetes, internal services are not intended for end users but are crucial for the system’s operation. These services operate in the background, ensuring vital functionalities that enable the stable operation and management of the container environment. In this subsection, we will introduce key services within Kubernetes and explain their role in our infrastructure. We will describe each service’s primary functionality and examine alternatives we explored in making our decision.
Kubernetes Distribution: When choosing a Kubernetes distribution, we examined three options: Canonical MicroK8s, Red Hat OpenShift, and the basic “vanilla” Kubernetes distribution. “Vanilla” Kubernetes represents the unaltered version directly available in Google’s repository, without pre-installed applications or plugins. We went for the vanilla version as it provides flexibility and freedom of choice of the extensions.
MicroK8s is an excellent solution for quick experimentation and setting up the system on smaller devices with limited resources (e.g., Raspberry Pi). However, it has many pre-installed applications and uses Canonical’s Snap packaging system, which can complicate adjusting configuration files and accessing external services, such as the NFS server.
We ruled out OpenShift due to the complexity of managing security profiles that, for our use case, were excessive, requiring substantial effort to implement these profiles for each service. Therefore, we opted for the basic “vanilla” Kubernetes distribution, offering more flexible and straightforward customization tailored to our needs.
Kubernetes Package Deployment: To describe the implementation of services in Kubernetes, a straightforward approach is to write YAML configuration file(s) (also called manifest), which are then forwarded to Kubernetes via the command line. However, some services can be quite complex, leading developers to create service packages, making services more general-purpose and customizable through parameters. The most widespread packaging system is Helm, allowing for more portable and adaptable service packages. Helm uses YAML files as templates (much like forms), which are then filled out based on the provided parameters and sent to Kubernetes.
Network Operator: Kubernetes services must be interconnected to communicate with other services. We opted for the open-source Tigera Calico operator to manage interconnections. Given its prevalence and functionalities, we found it the most suitable solution.
Calico and Flannel are the most common solutions for network operators. Flannel is more minimalistic and operates as a network switch (layer 2) using technologies like Open vSwitch or VXLAN. In contrast, Calico routes traffic like a network router (layer 3). Especially in cases of multi-cluster (i.e., multiple physical locations) or hybrid cloud services, Calico emerges as a better choice.
Storage Operator: For effective storage management within the Kubernetes system, we used csi-driver-nfs. It allows us to use the already established NFS servers. With it, we ensure uninterrupted access to persistent storage for any service within our private cloud.
The csi-driver-nfs proved most suitable since we already had an NFS server on one of the nodes. It allows us straightforward and centralized storage management for all services within Kubernetes. Centralization brings about numerous advantages, yet also challenges. Among the latter is the system’s vulnerability during a potential outage of the node storing the data. Nonetheless, centralization facilitates easier troubleshooting and backup execution.
Bare-Metal Ingress Load-Balancer: To ensure balanced ingress (of incoming) traffic among entry points in our Kubernetes cluster, we decided to utilize the MetalLB solution. After thorough research, we could not find any other alternative. Most of the online documentation (e.g., tutorials, blogs) focuses on setting up infrastructure on public clouds such as AWS or Azure and using solutions tailored to the demands of public cloud providers. However, since our infrastructure is based on our hardware (i.e., bare-metal), we opted for MetalLB, which has proven reliable and effective in routing traffic among our Kubernetes cluster’s entry points.
Ingress Operator: While a network operator manages interconnection between services within Kubernetes, the ingress operator manages access to services from the outside world. For security reasons, direct access to the internal network is prohibited. While it is possible to enter the internal network through a proxy (i.e., kubectl proxy), that’s meant only for debugging purposes. The ingress operator is designed to resolve domain names and route traffic to the correct container and port, which we described in the service’s YAML manifest. Using domain name resolution has several advantages. Regardless of the service’s internal IP address, the ingress operator will always correctly direct traffic. The ingress operator can act as a load balancer when there is a high-traffic load, balancing traffic between multiple copies of service.
Among the most common solutions for ingress traffic management are NGINX and Traefik Ingress operators. We chose NGINX, but the operators’ interface is standardized, so there are almost no differences between the solutions. Regardless of the selected solution, once a new service is deployed, the operator will follow the service’s manifest and automatically route traffic to the appropriate container.
GPU Operator: For efficient management of access to compute accelerators, we decided to use the official NVIDIA GPU-Operator suite of services. This suite provides two distinct installation options for NVIDIA drivers. The first option leverages host drivers, while the second involves drivers packaged within containers. Initially, we opted for the first option, wanting to enable the use of accelerators outside the Kubernetes framework. However, due to issues with conflicting driver versions, we decided to utilize the drivers provided by the GPU-Operator.
User Services
In this section, we introduce the selected services available to end users of our private cloud, enabling efficient execution and management of their research and educational projects.
JupyterHub is one of the key services in our private cloud, providing users with easy access to computing resources, data, and Jupyter Notebooks for research and teaching purposes. To implement JupyterHub, we use the Z2JH (Zero-to-JupyterHub) implementation, developed by a team of researchers at the University of Berkeley in collaboration with the Jupyter community. This solution facilitates quick setup and maintenance.
Every individual user is granted access to an isolated container instance via their username and password or OAuth provider, such as GitHub, Google, or Auth0. An isolated instance offers a stripped-down Linux environment with limited internet access and without admin permissions. Kubernetes then ensures access to shared data resources, common directories, and the use of compute accelerators.
The JupyterHub user interface is similar to Google Colab or Kaggle services. Upon entering the isolated instance, JupyterLab is already running, and the user also has access to the Linux terminal. Additional tools and software packages can be installed using pip, conda, or mamba commands.
Grafana is a key service in our private cloud, facilitating a straightforward display of the current workload of the compute cluster and the availability of compute accelerators. This data visualization platform allows users to present information clearly and transparently, aiding them in making decisions regarding resource usage and optimizing their tasks. Utilizing Grafana ensures efficient and transparent resource monitoring, enhancing user experience. Data collection (Prometheus) and visualization (Grafana) are deployed by kube-prometheus-stack.
Deployment
In this section, we’ll present how we deployed our computing infrastructure. First, I’ll summarize the hardware decisions, caveats, and finally, the user experience with some screenshots.
Hardware
| Hardware | Specifications |
|---|---|
| Chassis | Supermicro A+ Server 4124GS-TNR, 4U size, up to PCI-E 8 GPUs |
| CPU | 2x AMD EPYC 75F3 (32C/64T, up to 4.0GHz, 256MB L3 cache) |
| Memory | 1TB (16x64GB) REG ECC DDR4, 3200MHz |
| System | 2x 2TB SSD NVMe, software RAID-1 (mirror) |
| Storage | 6x 8TB SSD SATA, software RAID-Z1 (1 disk redundancy) |
| GPU | 2x NVIDIA A100 80GB PCI-E |
When we bought the hardware in early 2022, we chose third-generation AMD EPYC processors. Specifically, we went for the F-series, which has higher base and turbo frequencies — up to 4.0GHz — at the cost of fewer cores. We picked a CPU with the highest available TDP of 280W. We installed server-grade registered error-correcting memory at the highest frequency supported by the processor and populated all eight channels on both processors. Sixteen sticks of RAM in total. Although we considered solutions from Intel, AMD EPYC processors had better price-to-performance ratios.
From the perspective of numerical performance, our significant concern was Intel-optimized libraries, such as Intel MKL, often found in numerical tools. The library has a “bug” that causes non-Intel processors to utilize a slower SSE instead of more advanced AVX vectorization instructions [src]. OpenBLAS is a good alternative but requires some effort to install it. See Anaconda no-mkl package.
We chose two NVMe drives configured in the mirror configuration (RAID-1) for the system drive. We selected six 8TB SSD SATA drives configured in ZFS RAID-Z1 for data storage, which has one drive redundancy. We also chose two A100 GPUs as accelerators.
NVIDIA A100 GPUs come in two form factors: PCI-E and SXM4. The SXM4 proprietary form factor has a higher TDP and high-bandwidth NVLink interconnections between every GPU through NVSwitch hardware. The downside of SXM4 is that it will only support Ampere generation GPUs and require a special motherboard. The PCI-E variant has a lower TDP, and NVLink can only be across two GPUs. However, we decided against vendor lock-in, limiting ourselves to one brand and generation, and went with the PCI-E variant.
We considered the most likely workflow scenarios. We expected most communication to be CPU-to-GPU, with GPUs sliced into several instances via MIG (Multi-Instance GPU). When MIG mode is enabled, each GPU is partitioned into isolated instances that share the physical GPU resources but do not have access to NVLink interconnects. The slicing configuration can be changed at runtime by recreating the MIG instances.

User Experience
After deploying the hardware and software stack, we conducted a month-long live test to stabilize the configuration. During this period, users were informed that we might reboot the system or make significant changes without responsibility for any potential data loss, though we aimed to minimize such occurrences.
We made two key decisions about resource allocation. Users can utilize all available memory and CPU cores. When CPU demand is high, Kubernetes and the operating system manage the scheduling of tasks. In cases of high memory usage, the job consuming the most memory is terminated to protect other running tasks.
Feedback from students and researchers was overwhelmingly positive, highlighting the high speed, numerous cores, ample memory, and dedicated GPU access without interference.
During the testing phase, “testers” identified several issues, which were promptly addressed. These included adding a shared folder with datasets and Jupyter Notebooks, shared package cache, and better persistence of running tasks in JupyterLab.
JupyterHub
JupyterHub has become a crucial component of our research infrastructure, enhancing our workflow significantly. Its smooth integration was largely due to the interface and functionality of JupyterHub, which closely resemble the tools our researchers and students were familiar with. This similarity played a key role in its quick adoption and high user satisfaction.
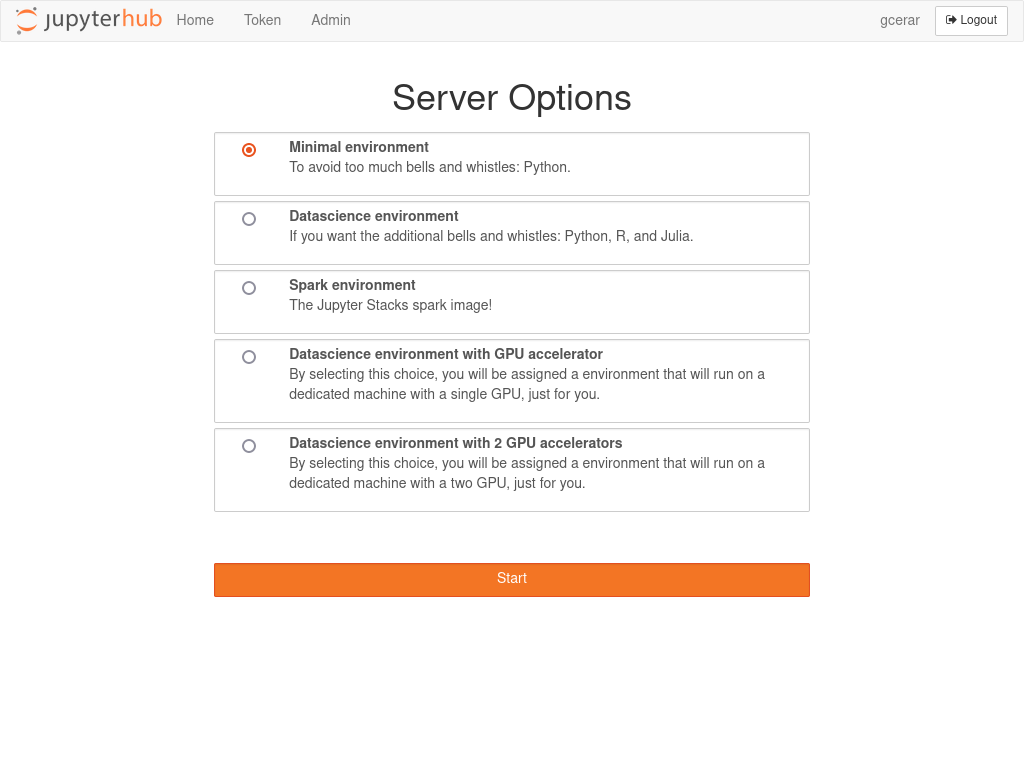
Upon logging into JupyterHub, users are presented with a list of predefined containers (as shown in Figure 3). Our recent update includes several options:
- A basic minimal working environment.
- A comprehensive data science environment equipped with multiple packages and support for Python, R, and Julia.
- A selection of containers offering GPU instances.
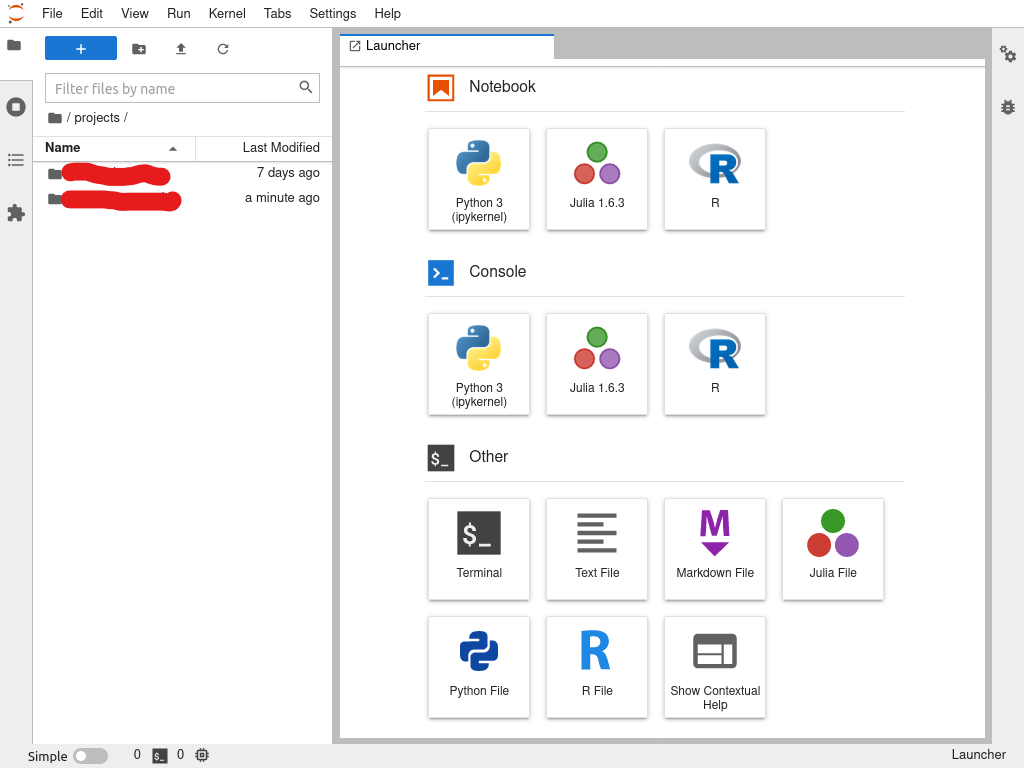
The development environment greets users with a layout similar to modern IDEs, featuring a file explorer on the left and code editor tabs on the right (see Figure 4).
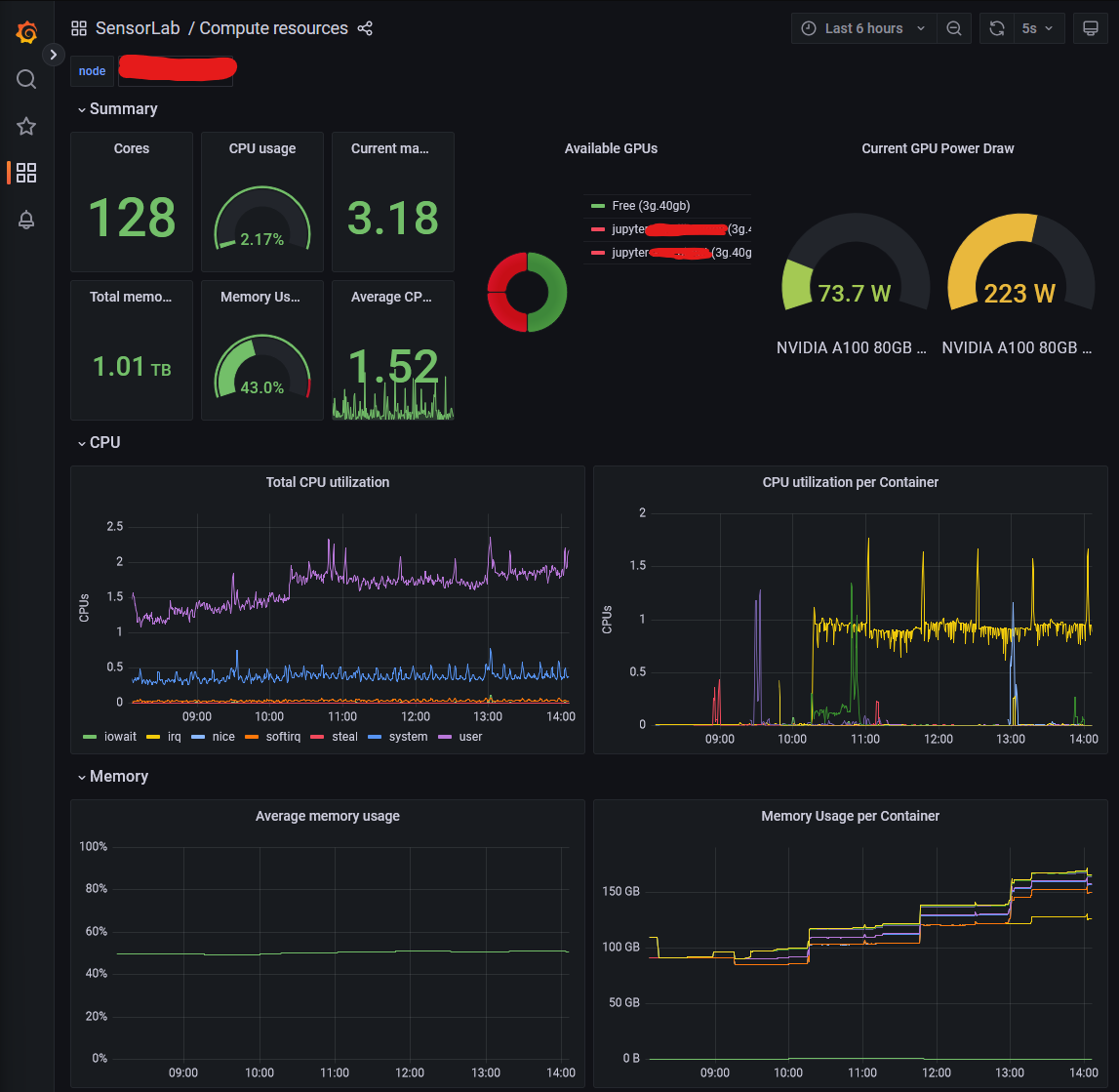
Grafana
For transparent insight into infrastructure availability, the user has read-only access to the Grafana dashboard. Dashboard visualizes computing resource utilization including metrics like total and per-container CPU usage, memory usage per container, GPU utilization, temperature readings, and storage I/O (see Figure 5).
Conclusions
This article introduced our private cloud solution based on Kubernetes technology. This solution offers a scalable environment for using Jupyter Notebooks, an effective educational tool for data-driven narrative analysis, creating learning materials, and interactive presentations. Additionally, the system allows for the concurrent sharing of computing resources, significantly enhancing the utilization of our entire infrastructure.
The JupyterHub service on the Kubernetes platform facilitates easy access to the work environment and ensures user isolation, allowing for uninterrupted work and research. Users benefit from storage space and shared folders for file sharing, promoting collaboration and teamwork. Users also have access to compute accelerators when available.
We discuss our solution’s key components, architecture, and design decisions, revealing the technology choices that led to efficient operation and an exceptional user experience. Our focus has been on open-source platforms that have proven reliable and effective in our environment. As the core platform, Kubernetes enables scalable container management and high availability, while JupyterHub provides easy access to services and simplifies user management.
We plan to enhance our solution with additional services and technologies to improve user experience and increase our cloud’s performance. We remain open to new technologies and approaches that contribute to the better functioning of our private cloud solution for research and education. Data from Prometheus will be crucial for analyzing infrastructure utilization and understanding the extent of user competition for computing resources.